After setting up a hello world application in Scala and Tapestry, and testing how Tapestry IoC / property access works in this environment, it's time to actually do something.
So, this article will explain how I set up the basic fonctionnalities for our blog:
- build a "Layout" component, so that the development will hurt our eyes a little less;
- add an Article object, and the standards pages to use it:
- the "home page" page will show all the published articles;
- a "create" page will allow to add new article;
- a "view" page will show only one article and its comments
- a "manage" page will allows to view a list of all the article with some actions, like publish, delete, edit.
Setting up a layout
Using "layout" is a common pattern to apply the same design for all the site. In tapestry, no need to use an external template engine like sitemesh, you can simply build a "layout component" that you will use on all page that have to be decorated.
This pattern is so common that Tapestry 5
has a documentation page on how to do it with T5, so you just have to follow it : the harder part is to design the layout, or if, like me, you are a dumb in design, find a cool CSS/HTML template on internet (thank you
Free CSS Templates for the one I chose.
As it's the first time that we will build a Tapestry 5 component, I will details a little what we need. In Tapestry 5, component are simple POJOs. They go under the ${t5-root}/components package, and are coupled with a Template (.tml) file.
- create the ${root}/components/Layout.tml and ${root}/components/Layout.java couple of files for our component;
- add the needed CSS/images in the webapp directory.
The code for the layout is here:
@IncludeStylesheet(Array("context:css/red/style.css"))
class Layout {
@Inject @Property
var conf : BlogConfiguration = _
}
The interesting part is the @IncludeStyleSheet annotation, that say to T5 ti add it the given CSS into the header of the pages where this component is used, what is handy for a layout component.
We can see that in Scala, we can't simply use the
@IncludeStylesheet({"context:css/red/style.css"}) notation, and have to explicitly build a new array - hopefully, it's trivial in Scala.
The template part of the component is bigger, since it's there that goes all the common HTML declaration.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:t="http://tapestry.apache.org/schema/tapestry_5_0_0.xsd">
<head>
<title>${conf.blogTitle}</title>
<meta http-equiv="Content-Language" content="English" />
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
</head>
<body>
<div id="wrap">
<div id="header">
<h1><a t:type="pagelink" t:page="index">${conf.blogTitle}</a></h1>
<h2>${conf.blogDescription}</h2>
</div>
<div id="menu">
<ul>
<li><a t:type="pagelink" t:page="index">Home</a></li>
[...]
</ul>
</div>
<div id="content">
<div class="left">
<t:body />
</div>
<div class="right">
<h2>Archives</h2>
<ul>
[... here will go the archives ...]
</ul>
<h2>Tags :</h2>
<ul>
[... here will go tags link ...]
</ul>
</div>
<div style="clear: both;"> </div>
</div>
<div id="bottom"> </div>
<div id="footer">
Designed by <a href="http://www.free-css-templates.com/">Free CSS Templates</a>
</div>
</div>
</body>
</html>
The important part it the
<t:body /> tag, that says "here will go what will be find between the <t:layout> and </t:layout> tags. So, in the page where we want to use this layout, we will use template code like:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<t:layout xmlns:t="http://tapestry.apache.org/schema/tapestry_5_0_0.xsd">
<h2>New article</h2>
[....]
</t:layout>
And now, our blog is prettier:
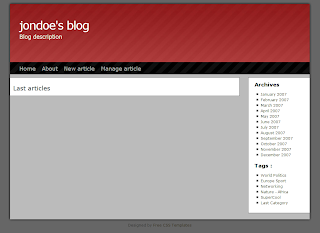
Note: I equally use <htmlTag t:type="T5_component"...> and <t:="T5_component"> notation to include T5 component in templates. The first one is better for designer, as template preview is correct, the second one is a little shorter. They are equivalent, and I should homogeneously use one or the other...
Article's CRUD
All this blog application is a pretext for that very part, so let's take a look at it. Reminder: "CRUD" stands for "Create, Retrieve, Update, Delete", and is a well know acronym that is used for simple application, with very little domain logic, and which are almost a front-end for datas, persisted in some layer (MySQL comes to mind, but CouchDB is a better buzz word today ;)
To sum-up, we have Article objects, a DAO to persist them, and a couple of pages to enable human I/O.
The "Article" domain object
An article is an object with an id, a title, a content, a list of comments and a creation date.
The "id" is unique identifier for an article among all the blog's article. Most of the time, it will be used to identity a particular article in the persistence layer or in URL.
I take the choice to let the persistance layer assigned the id, because we really are in a CRUD application, and no business logic can provide a realiable unique identifier. That means that a not yet persisted article has no id. In the same time, I want to enforce the fact that Id are imutable datas, that given a Article object, the id won't ever change.
In java, this kind of requirement can't easily be done in an other way than usgin "null". In Scala as in many other language, we have an
Option type that has two kind of value:
- the "None" value, which means "there is no data here";
- the "Some[TypeOfData]" value, which means "there is a data here, and that is it's value".
I use this type for the article "Id", and the "Id" is a constructor param value of article, so that:
- article id is immutable: an living object can't have it's id change;
- an article with "None" id has never been saved ;
- the persistence layer will assign IDs and return article with there definitive ID
Given that, that's the code for the Article object:
org.example.blog.data.Article.scala
class Article(val id:Option[String]) {
/*
* "none" is not allowed for article ID
*/
assert( id.forall( (s:String)=> !(s.toLowerCase == "none" )))
@BeanProperty var creationDate = new Date()
@BeanProperty var title = ""
@BeanProperty var content = ""
@BeanProperty var comments = List[Comment]()
@BeanProperty var published = false
def getId = id
/*
* String translation of the ID. Of course, it
* requires that id can't be the "None" String,
* and that's why we add the "assert" requirement
*/
def getDisplayId = this.id.getOrElse("None")
}
object Article {
/*
* Create a copy Article from a source one,
* setting the ID to a new value.
*/
def apply(id:String, source:Article) : Article = {
val a = new Article(Some(id))
a.title = source.title
a.content = source.content
a.comments = source.comments
a.creationDate = source.creationDate
a.published = source.published
a
}
}
Apart from the Article constructor and "Id" type explained before, there is three other notable things in this class:
- A getDisplayId that is a simple method to give the article Id to other layer, especially the presentation layer. I chose to map "Some(id)" to the given id string, and the "None" type to the "None" string, what implies that I should never accept the "None" id;
- since I can't accept "None" string as id, I added a requirement through an assertion (and no, performances don't matter, it's a tool blog application ;)
- finally, there is a strange "object" definition after my class with the same name as it, that needs its own paragraph
"objects" are the Scala way to define static methods and contents, and it's why I used the "object" key word in the AppModule.
When paired with a class, it is called a companion object for the class. They have some special rights, in particular regarding visibilyity, that goes beyond this article.
I used this one to create a "copy" method that allows to create an article with a given id, different from the source - remember, I want to have immutable ids for an Article for all is life in memory.
The question is "why do I called this method
apply, what is a name that carry almost zero information ?". Simply because it's a Scala magic word, that can be zapped when used ! Just writing
"Article(id, article)" will call Article.apply(...). If you remember the "Array" in the @IncludeStyleSheet for the layout... That was the same principle. Array is the companion object of the Array class, and "Array("...","...")" secretly call the "apply" method of Array that take a list of String as parameter.
And we are done with Articles.
DAO
A DAOs ("Data Access Objects") are objects responsible for accessing and persisting (or delegate persistence of) other objects. They are the heart of CRUD application.
The first paragraph explain our generic DAO API, the second will show a naive, in memory implementation of the generic DAO for article, and a third one will explain how to use it with Tapestry IoC.
Generic DAO API
We will define DAO by their API, the set of method exposed by these service objects. In Java, API means "Interfaces", in Scala they means "Traits". In our example, they are the same things. We will define a real implementation
org.example.blog.services.DAO.scala
/**
* A read-only dao
* @param T is the type of entities handled by this DAO
* @param K is the type of the key that is used to identify entities.
*/
trait ReadDao[T, K <: Serializable] {
/*
* Retrieve an entity from its key. If no
* entities are known for the given key, None is returned.
* @param K the unique id of the entity to fetch
* @return None if no entity match that key,
* Some[entity] else
*/
def get(id:K) : Option[T]
/**
* Retrieve all the entities known by that DAO.
* Be carefull, that may be a huge number.
* @return the list of all entities for that DAO
*/
def getAll() : List[T]
/**
* Find all the entities that match the given requirement
* @param T => Boolean : the function to apply to find if
* an entity should be included in the returned list.
* (on a "true" return) or excluded (on a "false" return)
* @return the list of enetities matching the filter.
*/
def find(filter: T => Boolean) : List[T]
}
/**
* A write-only dao
* @param T is the type of entities handled by this DAO
* @param K is the type of the key that is used to identify entities.
*/
trait WriteDao[T, K <: Serializable] {
/**
* Persist the given entity: create a new one if
* the entity wasn't know in that DAO (entity
* key was None), or update an existing entity
* (it's key was Some[K]).
* @param T the entity to persist
* @return the key of the persisted entity if the process
* succeded, or None the the peristence failed.
*/
def save(entity:T) : Option[K]
/**
* Delete the article matching this id.
* If no article match this id, does nothing.
* Return true is the deletion is successful
*/
def delete(id:K) : Boolean
}
/**
* A read-write DAO, that combine read and write DAO traits.
*/
trait ReadWriteDao[T, K <: Serializable] extends ReadDao[T,K] with WriteDao[T,K]
Comments speak for themselves here, and "Option" is well-known now.
The only surprises are the "<:" which means that the K type has to be Serializable, and more notably for a Java guy, the "find" method: it takes a method as parameter !
The signature of the filter method is "I take an entity of type T as parameter, and return a Boolean".
For example, if we take an Article DAO, we may use this to find all the article whose title begin with "The" like that:
val articles = dao.find( (a:Article) => a.title.startsWith("The") == true )
That's all. It means "the method find takes as parameter a method that take an article as parameter, and return the result of the evaluation of "a.title.startsWith("The") == true".
It can even be simpler, because Scala allows to use "_" as a place-holder for parameter when there is no ambiguities, like here (in our case, find can't take anything but a method which has the "Article => Boolean" signature):
val articles = dao.find( _.title.startsWith("The") == true )
If you don't see why "closure" are so useful, look how simple that declaration is compared to the burden to declare a filter interface and used it, even with anonymous class in place of real instances...
In memory Article DAO
Now that we have our generic DAO API, we are ready to implement a version for Articles. This first DAO will be a really simple one, where articles are persisted in memory (in a Map).
org.example.blog.services.impl.dao.InmemoryDao.scala
import org.example.blog.data.Article
import scala.collection.mutable
import org.example.blog.services.ReadWriteDao
/**
* A simple, naive implementation of the Article DAO.
* In particular, this implementation is
* NOT AT ALL THREADSAFE
*/
class InmemoryArticleDao extends ReadWriteDao[Article, String] {
private val memory : mutable.Map[String, Article] = new mutable.HashMap()
private var id = 0
private def newId = { id = id + 1 ; id }
def get(id:String) = this.memory.get(id)
def getAll() = this.memory.values.toList
def find(filter: Article => Boolean) =
(for {
a <- this.memory.values
if(filter(a))
} yield a).toList
def save(article:Article) = {
val a = article.id match {
case None =>
val i = this.newId
Article(i.toString,article)
case Some(id) => article
}
assert(a.id.isDefined)
this.memory.put(a.id.get,a)
//check if article is in map for the id, return id if OK
this.memory.get(a.id.get).map( _.id.get)
}
def delete(id:String) = !( (this.memory - id).isDefinedAt(id) )
}
We can see that the "extends ReadWriteDao[Article, String]" is really like Java with generics.
The implementation is a basic mapping between our DAO API and the Map used as a back-end. Article Ids are generated by an incrementing number, but there's no lock against thread concurrency. Say that for now, it's really a tool example, and all in all, our blog can have only one author (reminds the configuration object of the previous post).
The save method is the most complex, because we have to process the update and the create case, based on the fact that id is None or Some(value).
We also see the use of the Article companion object "apply", that allows to copy the given article to a new one, but with it's freshly created id.
The filter method the Scala for comprehension loop that automatically concatenates yielded elements, but it could have been done with an even more imperative "for" loop too:
def find(filter: Article => Boolean) = {
var articles = List[Article]()
for(a <- this.memory.values) {
if(filter(a)) articles = a :: articles
}
articles
}
I believe that the first method is better, because the two are almost as inefficient, and the latter use a mutable variable.
That's all for the implementation of our DAO !
Enable Article DAO service thanks to T5 IoC
Now that we have a DAO API, and a DAO implementation for Article, we want to let our application know that when we use a DAO on articles, what we really want is to use the "In Memory Article DAO".
As for the Configuration service on the previous post, we just have to add a "build" method into the AppModule object to bind the ReadWrite[String,Article] DAO to its implementation:
def buildArticleDao = new InmemoryArticleDao()
Hum. Yeah, there is nothing to do but that, but as we are Professional, we can't let our bosses think that our job is so simple, so let's add some boilerplate to make the code seems harder, more complex:
def buildArticleDao = {
val a1 = new Article(None)
a1.title = "First article"
a1.content = "Content for the first article"
a1.published = true
val a2 = new Article(None)
a2.title = "Second article"
a2.content = "Content for the second article"
val m = new InmemoryArticleDao()
m.save(a1)
m.save(a2)
m
}
OK, that's better ! Actually, I just initialized the DAO with two articles (one published, not the other one), but it's far more impressive like that ;)
Putting the parts together : the presentation layer
Now that we (finally !) have all the services to create and retrieve articles set-up, we can switch to the only part in which customers have some interests, the presentation layer (that's because code screenshots look bad on powerpoint).
The Index page
The first page that will use our new services is the home page. On this page, we just want to display all published articles.
For that, we will use the
Loop component:
org.example.blog.pages.Index.tml
<t:layout xmlns:t="http://tapestry.apache.org/schema/tapestry_5_0_0.xsd">
<div t:type="loop" t:source="articles" t:value="article" class="article">
<h2><a t:type="pagelink" t:page="article/view" t:context="article.displayid">
${article.title}
</a></h2>
<div>${article.content}</div>
</div>
</t:layout>
We see in this template that we link to the "article/view" page, in which we will display the article with its comments. But as it's for an other day, for now we just create a org.example.blog.page.article.ViewArticle.{scala,tml} couple so that Tapestry 5 don't stop on a broken link (it validate that all lins are correct at start time), and we will take care of them the next time.
We also see that we need a "source" from where articles are taken, and a "value" to hold the current article of the loop. Of course, these objects are provided by the Scala part of the couple:
org.example.blog.pages.Index.scala
class Index {
@Inject
var readArticleDao : ReadDao[Article, String] = _
@Cached
def getArticles = readArticleDao.find( _.published == true ).toArray
@Property
var article : Article = _
}
The code stands for itself : we inject a read-only DAO for article - we don't need more, and even if actually we get the in memory read write implementation, this code only care for the read part ; we have a "getArticles" method that retrieve all publish articles from the DAO (remember: closures are great), and we have an Article "@Property" annotated to receive the current article from the loop.
As we have initialized the DAO with two articles (one published among them), as soon as we start the application, we can see the first, published article on the home page:

Isn't that great ?
Create new articles
Now that we can see our article, we may want to add some new ones - well, it's aim to be a blog, and what the point if I can't talk about how cute is my ickle hamster ?
For that, let's build the "create article" page.
Let's begin with the template. In this first version, I won't rely on the magc BeanEditForm, and we need to be able to set a title, a content, and choose to publish or not the article:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<t:layout xmlns:t="http://tapestry.apache.org/schema/tapestry_5_0_0.xsd">
<h2>Create a new article</h2>
<t:form t:id="NewArticleForm" class="new-article">
<p>
<t:label for="publish" /> <t:checkbox t:id="publish" t:value="article.published" />
</p>
<p>
<t:label for="title"/><br/>
<t:textfield class="large" t:id="title" value="article.title" validate="required"/>
</p>
<p>
<t:label for="content" /><br/>
<t:textarea class="large" t:id="content" value="article.content" />
</p>
<t:submit />
</t:form>
</t:layout>
This template is a little boring, but it's the first time we see a constructed form and it's different input. The title is required, and the form will be refused as long as it is no provided. There is other predifined validator, like min/man, regexp... And... well, there's nothing more to say : all input has a value parameter that is the link to the server-side java^W Scala object that will handle it, and there is a submit button. And that's all.
That looks like that:
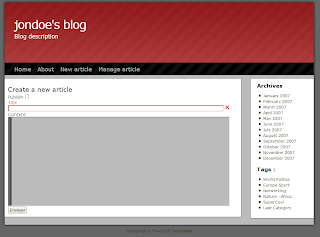
Ok, so how do we handle that on the server side ?
org.example.blog.page.article.CreateArticle.scala
import org.apache.tapestry5.annotations.{Property,Persist,InjectPage}
import org.apache.tapestry5.ioc.annotations.Inject
import org.example.blog.data.Article
import org.example.blog.services.WriteDao
import java.text.DateFormat
class CreateArticle {
@Inject
var articleDao : WriteDao[Article,String] = _
@Persist @Property
var article : Article = _
@InjectPage
var redirectPage : ManageArticle = _
def setupRender {
if(null == this.article) {
this.article = new Article(None)
}
}
def onSuccessFromNewArticleForm = {
articleDao.save(article) match {
case None => error("Dao error ! Please retry.")
case _ => this.article = null ; redirectPage
}
}
}
This time we need the "Write" part of the DAO (and a again, no need for the other, so I injected the minimal aspect), and an Article that will back the the new article.
The article is annotated @Persist, so that it will be stored in session. We need that because the form has to be validated, and perhaps show again: we don't want to loose what was written in this case.
The setupRender method is a conventional name that matches a
component rendering phase. We will take advantage of this method to initialized a new Article, if needed.
The onSuccessFromNewArticleForm is again a conventional method name to handle a component event. On that case, the event is "success", and we await it from the "articleForm" component... which is our form's "t:id". So, you get it, when the form succeed, we go into that method, in which we try to save the Article. If the DAO failed in its job, we raise an error, and else we redirect into the ManageArticle page. There is a lot of way to redirect to a page in T5: you can use URL, page class, the string page name, or the InjectPage annotated page. This method is handy when you need to init some value in the page before redirecting to it. Well, here it's just because it's cool ;).
And now, we are redirected to the "manate" page.
Manage all articles
The goal of this page is to give the author the possibility to view the list of all existing articles. Moreover, we want to be able to go there detail page, to publish or unpublish, edit and delete them.
In this case, the perfect component is
the grid component.
This component allows to display a list of beans, one column by property, and allows to add, remove, reorder columns.
The template looks like that:
<t:layout xmlns:t="http://tapestry.apache.org/schema/tapestry_5_0_0.xsd">
<h2>List, modify, publish article</h2>
<t:grid source="articles" row="article"
reorder="title" exclude="content" add="comments,publish,edit,delete">
<t:parameter name="titleCell">
<t:pagelink t:page="article/view" t:context="article.displayid">
${article.title}
</t:pagelink>
</t:parameter>
<t:parameter name="publishCell">
<t:actionlink t:id="changePublication" t:context="article.displayid">
${changePublication}
</t:actionlink>
</t:parameter>
<t:parameter name="commentsCell">
${article.comments.size()}
</t:parameter>
<t:parameter name="editCell">
<t:pagelink t:page="article/edit" t:context="article.displayid">
edit
</t:pagelink>
</t:parameter>
<t:parameter name="deleteCell">
<t:actionlink t:id="delete" t:context="article.displayid">
delete
</t:actionlink>
</t:parameter>
</t:grid>
</t:layout>
What looks in real like:
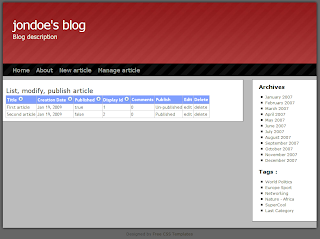
There is some interesting things in this template:
- we have a source of bean, and the current Article is handle in the "row" parameter;
- the "t:parameter" is special invocation that allows to bind a block of template code to component parameter. In our case, each t:parameter is used to replace the content of a column cell;
- the pagelink component has already been seen several times, but here can see how easy it is to map page to URL: it's simply the list of directories from the "pages" package to the page object. We also see how we can pass a some context (variable) into the targeted page;
- lastly, the "t:actionlink" is a component that allows to fire an event on the server side;
So, how we handle all that on the server side ?
org.example.blog.pages.article.ManageArticle.scala
class ManageArticle {
@Inject
var rwDao : ReadWriteDao[Article, String] = _
@Property
var article : Article = _
def getArticles = this.rwDao.getAll.sort( _.creationDate.getTime > _.creationDate.getTime ).toArray
def getChangePublication = if(article.published) "Un-published" else "Published"
def onActionFromChangePublication(id:String) {
val a = this.rwDao.get(id).getOrElse(error("No such article, id: " + id) )
a.published = !a.published
this.rwDao.save(a)
}
def onActionFromDelete(id:String) {
if(!this.rwDao.delete(id)) {
error("Can not delete this article")
}
}
}
The code is fairly simple and clear:
- we need the ReadWriteDao, so we inject it;
- we need an article to keep the current row, so we add an @Property annotated Article;
- the source of all bean is provided by the "getArticles()" method, that simply retrieve all the articles from DAO (and sort them by date);
- the "getChangePublication()" return the good text given the status of the article;
- the "onActionFromChangePublication" method handle the event from the actionLink with "t:id" changePublication. The method await a parameter which is given by the context of action link (and is the article id). We react at this event by changing the status of the matching article, and save it back into the DAO;
- finally, the "onActionFromDelete" handle the event from the "delete" link, and react to it by deleting the article from the DAO.
Note that all event handler that does not return anything redirect to the calling page.
Final words
Conclusion
And that's done ! The goal perimeter is reached, we can see, add, manage articles in a not too ugly blog.
Now, a lot of things remained:
- Articles are not really persisted, and are lost on server shutdown. What abot saving them into a database, or even better into a more "text oriented" storage, has XML files, or something like a Java Content Repository (or a CouchDB ?)
- Where are the comments ?
- And the article details ? And all the formating of articles is lost in rendering ! That's awful ! Perhaps we need a smarter rendering component... and so we may used it at several place around the site (Index, article details...)
- And what about a better text editor, that allows some kind of rich UI ? Personally, I really like showdown editor
- And tags, hu ? We are building the tomorrow blog plateform for web 3.0 and don't even have tags ? That can't be serious !
- oups, somebody just pointed that for now, there is no way to protect the manager area from the simple user... No authentication, no authorizations...
- I also said that I will attempt to use easy-ant as build tool, in place of maven
- and the list is almost infinite !
So, there is still some room to a little more experiment with T5 and Scala !
Source code
As always, the source code is available on the GitHub repository of the project.
To download and test the code for that articles, simply executes these commands:
% git clone git://github.com/fanf/scala-t5-blog.git
% cd scala-t5-blog
% git checkout -b test article3_20090119
% mvn jetty:run
Enjoy, and see you next time !






